本篇文章介绍如何通过将多个提示词结合起来,将复杂的任务分割成一系列更简单的子任务。
对于一个复杂的任务,我们可以通过一个复杂的提示词,让模型进行思维链推理,从而一步一步处理复杂任务。另一方面,我们也可以将一个复杂任务分成多个子任务,每个子任务都由一个单独的prompt去驱动模型处理。这样组织prompt的形式成为链式提示。
那么在什么情况下,我们需要将一个复杂任务拆分成多个子任务来处理呢?
本篇文章介绍如何通过将多个提示词结合起来,将复杂的任务分割成一系列更简单的子任务。
对于一个复杂的任务,我们可以通过一个复杂的提示词,让模型进行思维链推理,从而一步一步处理复杂任务。另一方面,我们也可以将一个复杂任务分成多个子任务,每个子任务都由一个单独的prompt去驱动模型处理。这样组织prompt的形式成为链式提示。
那么在什么情况下,我们需要将一个复杂任务拆分成多个子任务来处理呢?
对于一个机器人问答系统,用户的提问多种多样。为了更好的应对用户的提问,将用户的提问进行分类,然后根据不同的提问类别针对性地回答问题。这样系统会显得更智能。
在篇文章中,我们将重点关注如何对用户的输入进行分类。这对于确保系统的质量和安全性非常重要。对于需要处理具有大量独立指令集的任务,首先对问题类型进行分类,然后根据分类结果确定使用哪些指令,这对整个问答系统是非常有益的。
在本篇文章中,我们将综合前面文章中所有知识,创建一个端到端的客户服务助理示例。我们将经历以下步骤:
首先,我们将通过Moderation API检查输入是否违规。
其次,如果没有,我们将提取产品列表。
第三,如果找到产品信息,我们将尝试查找它们。
第四,我们用模型回答用户的问题。
第五,我们将通过Moderation API对答案进行审核。如果回答没有违规,我们可以把它返回给用户。
第六,对模型的回答进行质量评估
1 | %env OPENAI_API_KEY=sk-XXX |
获取openai开放的模型列表:
1 | import openai |
大型语言模型的一个令人兴奋的方面是,你可以利用它来构建一个定制的聊天机器人,并且只需付出少量的努力。ChatGPT 的网页界面可以让你与一个大型语言模型进行对话。但其中一个很酷的功能是,你也可以利用大型语言模型构建你自己的定制聊天机器人,例如扮演一个人工智能客服代理或餐厅的人工智能点餐员的角色。本篇文章将揭晓如何做到这一点。
下面是两种调用OpenAI接口的函数。get_completion只支持单轮对话,意味着模型回答问题时不会考虑之前的对话信息。get_completion_from_messages支持多轮对话信息。这是因为它的参数message可以包含对话的上下文。下面我们看看它们在对话机器人中是怎么使用的。
最近debug程序真是越来越离不开ChatGPT了。将问题直接抛给ChatGPT大大提高了我查找问题的速度。很多时候我已经无需另外使用搜索引擎来查找资料了。
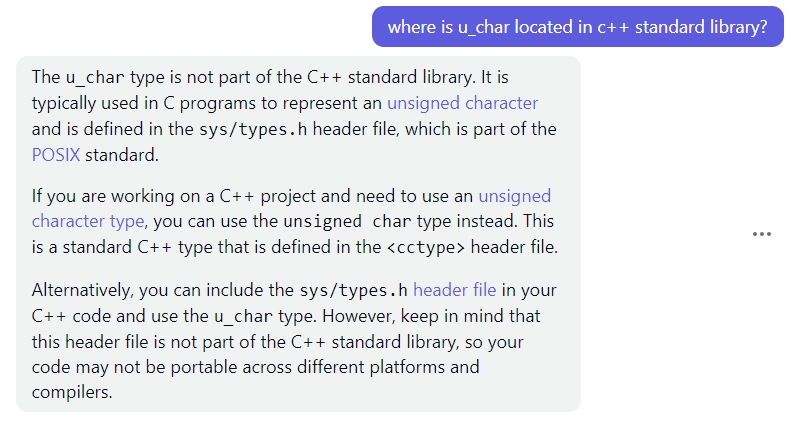
这个是我将一段Linux上运行的程序移植到Windows上运行时出现的问题。编译发现没有u_char这个类型。开始我以为是Linux和Windows上标准库不一致。向ChatGPT请教了一下,它直接告诉我这个类型是Linux的系统文件定义的。简单快速地解决了我的疑惑。
现在是信息爆炸时代,打开手机,各种文章扑面而来。我们的精力是有限的。如果有人帮忙把文章总结好给我们,这不就节省了很多时间嘛!我们也就可以阅读更多的文章了。
恰好大语言模型在总结文章方面非常有天赋。
